Code
library(tidyverse)
library(patchwork)
# Farben konsistent durch das gesamte Dokument
blau <- "#2C7BB6"
rot <- "#D7191C"
grau <- "grey50"
n_sim <- 1000 # Anzahl Simulationen (global)library(tidyverse)
library(patchwork)
# Farben konsistent durch das gesamte Dokument
blau <- "#2C7BB6"
rot <- "#D7191C"
grau <- "grey50"
n_sim <- 1000 # Anzahl Simulationen (global)Eine Studentin absolviert einen Test, welcher aus 15 Multiple-Choice-Fragen besteht. Sie hat sich gut vorbereitet und geht davon aus, dass sie jede einzelne Frage mit einer Wahrscheinlichkeit von 0.85 richtig beantworten wird. Für die Note 5.0 muss sie 80% aller Fragen richtig beantworten. Wie gross ist die Wahrscheinlichkeit, dass sie beim Test unter der erhofften Note 5.0 bleibt?
Definiert man die Zufallsvariable \(X\) als Anzahl richtig beantworteter Fragen, ist \(X\) binomialverteilt mit
\[X \sim B(15;\; 0.85)\]
Für eine Note von mindestens 5.0 müssen mindestens \(0.8 \cdot 15 = 12\) Fragen richtig beantwortet werden. Die gesuchte Wahrscheinlichkeit, unter Note 5.0 zu bleiben, ist also \(P(X < 12)\):
\[\begin{align} P(X < 12) &= 1 - P(X \geq 12) \\[4pt] &= 1 - \sum_{k=12}^{15} \binom{15}{k} \cdot 0.85^k \cdot 0.15^{15-k} \\[4pt] &= 1 - \bigl(0.2184 + 0.2856 + 0.2312 + 0.0874\bigr) \\[4pt] &\approx 0.18 \end{align}\]
Die Wahrscheinlichkeit, dass die Studentin unter den gegebenen Voraussetzungen die Note 5.0 verpasst, beträgt somit etwa 0.18.
n_fragen <- 15
p_richtig <- 0.85
# Einzelwahrscheinlichkeiten P(X = k) für k = 12..15
tibble(k = 12:15) |>
mutate(`P(X = k)` = dbinom(k, size = n_fragen, prob = p_richtig)) |>
knitr::kable(digits = 4,
caption = "Einzelwahrscheinlichkeiten P(X = k) für k = 12, …, 15")| k | P(X = k) |
|---|---|
| 12 | 0.2184 |
| 13 | 0.2856 |
| 14 | 0.2312 |
| 15 | 0.0874 |
# P(X < 12) = P(X ≤ 11)
p_unter_12 <- pbinom(11, size = n_fragen, prob = p_richtig)
cat("P(X < 12) = P(X ≤ 11) =", round(p_unter_12, 4), "\n")P(X < 12) = P(X ≤ 11) = 0.1773 cat("P(X ≥ 12) =", round(1 - p_unter_12, 4), "\n")P(X ≥ 12) = 0.8227 Die Wahrscheinlichkeit, die Note 5.0 zu verpassen, beträgt \(P(X < 12) \approx 0.18\).
Die Binomialverteilung \(\text{Bi}(n;\, p)\) mit \(p = M/N\) lässt sich als Grenzfall einer hypergeometrischen Verteilung \(\text{H}(N;\, M;\, n)\) auffassen, wenn \(n/N\) immer kleiner wird (in der Praxis z.B. ab \(n/N < 0.1\)). Dies soll hier illustriert werden.
Erzeugen Sie mit 1000 Beobachtungen eine Variable hypervar50, die hypergeometrisch verteilte Zufallszahlen mit \(N = 50\), \(M = 10\) und \(n = 10\) enthält, der hypergeometrischen Verteilung \(\text{H}(50;\, 10;\, 10)\) entsprechend. Erzeugen Sie anschliessend sukzessive weitere Variablen mit hypergeometrisch verteilten Zufallszahlen; dabei soll \(n\) konstant bleiben, und gleichzeitig sollen \(N\) und \(M\) so zunehmen, dass der Quotient \(p = M/N\) konstant bleibt. Führen Sie diesen Prozess so lange durch, bis sich die hypergeometrisch verteilten Variablen einer binomialverteilten Variable binomialvar nähern. Welche Binomialverteilung muss das sein? Stellen Sie die Verteilungen geeignet grafisch dar.
Parameterstruktur der hypergeometrischen Verteilung \(\text{H}(N;\, M;\, n)\):
| Symbol | Bedeutung |
|---|---|
| \(N\) | Gesamtanzahl Elemente in der Grundgesamtheit |
| \(M\) | Anzahl «Erfolge» in der Grundgesamtheit |
| \(n\) | Stichprobengrösse (Ziehungen ohne Zurücklegen) |
| \(p = M/N\) | Erfolgsanteil in der Grundgesamtheit |
Die Wahrscheinlichkeitsfunktion lautet:
\[P(X = k) = \frac{\displaystyle\binom{M}{k}\binom{N-M}{n-k}}{\displaystyle\binom{N}{n}}, \quad k = 0, 1, \ldots, \min(n, M)\]
Grenzübergang: Für festes \(n\) und festes \(p = M/N\) gilt:
\[\text{H}(N;\, M;\, n) \;\xrightarrow{\;N, M \to \infty,\; M/N \,=\, p\;}\; B(n;\, p)\]
Je grösser \(N\), desto kleiner ist der Einfluss des «Ohne-Zurücklegen» – die Verteilung nähert sich der Binomialverteilung (mit Zurücklegen) an.
Konkrete Parameterwahl (\(p = M/N = 0.2\) konstant, \(n = 10\) konstant):
| Variable | \(N\) | \(M\) | \(n\) | \(n/N\) |
|---|---|---|---|---|
| hypervar50 | 50 | 10 | 10 | 0.200 |
| hypervar100 | 100 | 20 | 10 | 0.100 |
| hypervar200 | 200 | 40 | 10 | 0.050 |
| binomialvar | \(\infty\) | – | 10 | \(\approx 0\) |
Die Grenzverteilung ist \(B(10;\, 0.2)\), da \(n = 10\) und \(p = M/N = 0.2\) konstant bleiben.
In R verwendet rhyper(nn, m, n, k) die Parametrisierung: m = \(M\), n = \(N - M\), k = Stichprobengrösse.
set.seed(42)
n_zug <- 10 # Stichprobengrösse (konstant)
p_hyp <- 0.2 # p = M/N (konstant)
# H(N; M; n): rhyper(nn, m = M, n = N-M, k = n_zug)
hypervar50 <- rhyper(n_sim, m = 10, n = 40, k = n_zug)
hypervar100 <- rhyper(n_sim, m = 20, n = 80, k = n_zug)
hypervar200 <- rhyper(n_sim, m = 40, n = 160, k = n_zug)
# Grenzverteilung: Bi(10; 0.2)
binomialvar <- rbinom(n_sim, size = n_zug, prob = p_hyp)# Empirische relative Häufigkeiten in langer Form
df_hyper <- tibble(
hypervar50 = hypervar50,
hypervar100 = hypervar100,
hypervar200 = hypervar200,
binomialvar = binomialvar
) |>
pivot_longer(everything(), names_to = "Variable", values_to = "x") |>
mutate(Variable = factor(Variable,
levels = c("hypervar50", "hypervar100", "hypervar200", "binomialvar"))) |>
count(Variable, x) |>
group_by(Variable) |>
mutate(rel = n / sum(n) * 100) |>
ungroup()
# Theoretische Bi(10; 0.2)-Wahrscheinlichkeiten
df_bi_theorie <- tibble(
x = 0:n_zug,
rel = dbinom(0:n_zug, size = n_zug, prob = p_hyp) * 100
)
ggplot(df_hyper, aes(x = x, y = rel)) +
geom_col(fill = blau, width = 0.7) +
geom_point(data = df_bi_theorie, aes(x = x, y = rel),
colour = rot, size = 2.5) +
geom_line(data = df_bi_theorie, aes(x = x, y = rel),
colour = rot, linewidth = 0.6, linetype = "dashed") +
facet_wrap(~ Variable, nrow = 2) +
scale_x_continuous(breaks = 0:n_zug) +
labs(x = "k", y = "relative Häufigkeit [%]") +
theme_minimal(base_size = 11) +
theme(strip.text = element_text(face = "bold"),
axis.text.x = element_text(size = 8))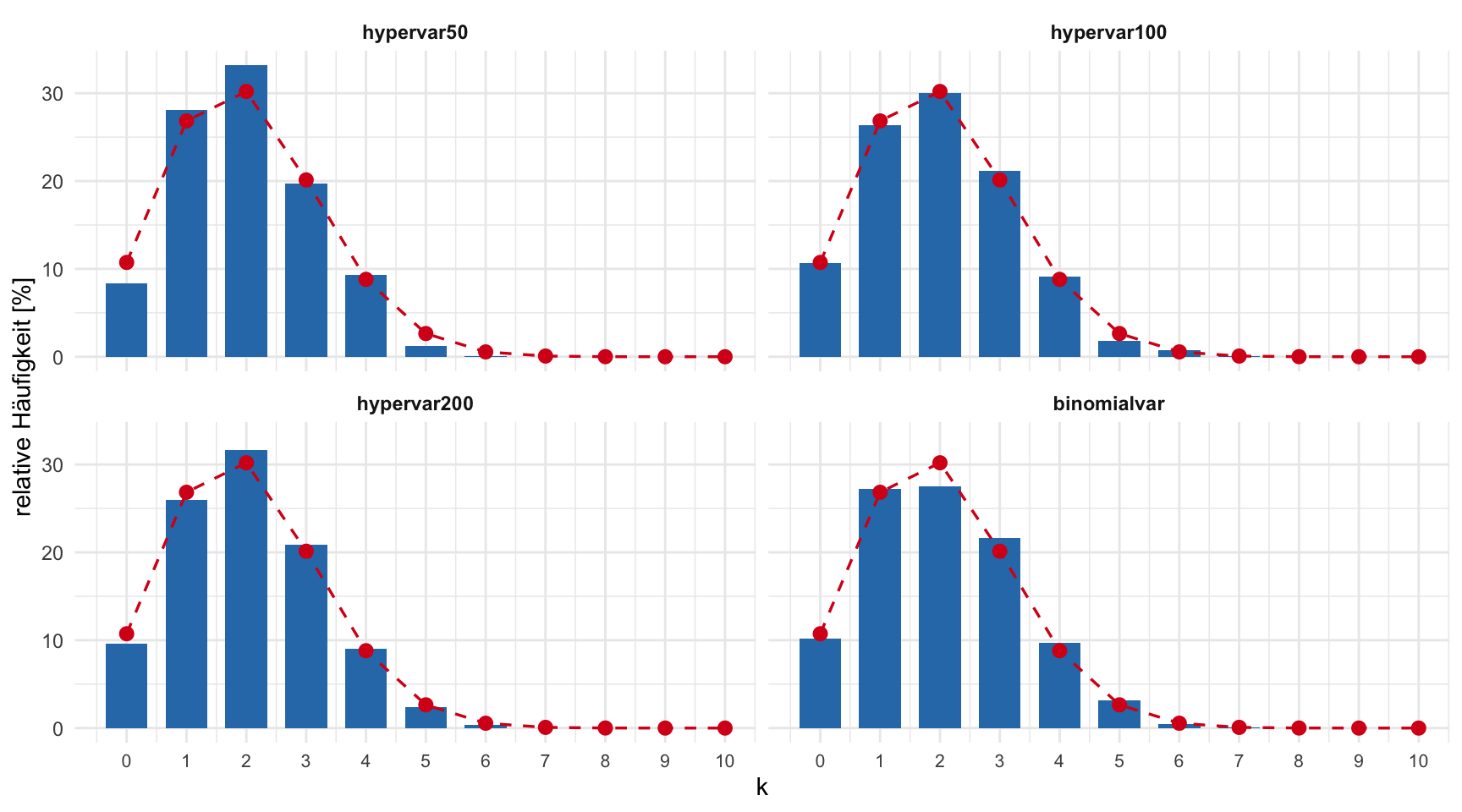
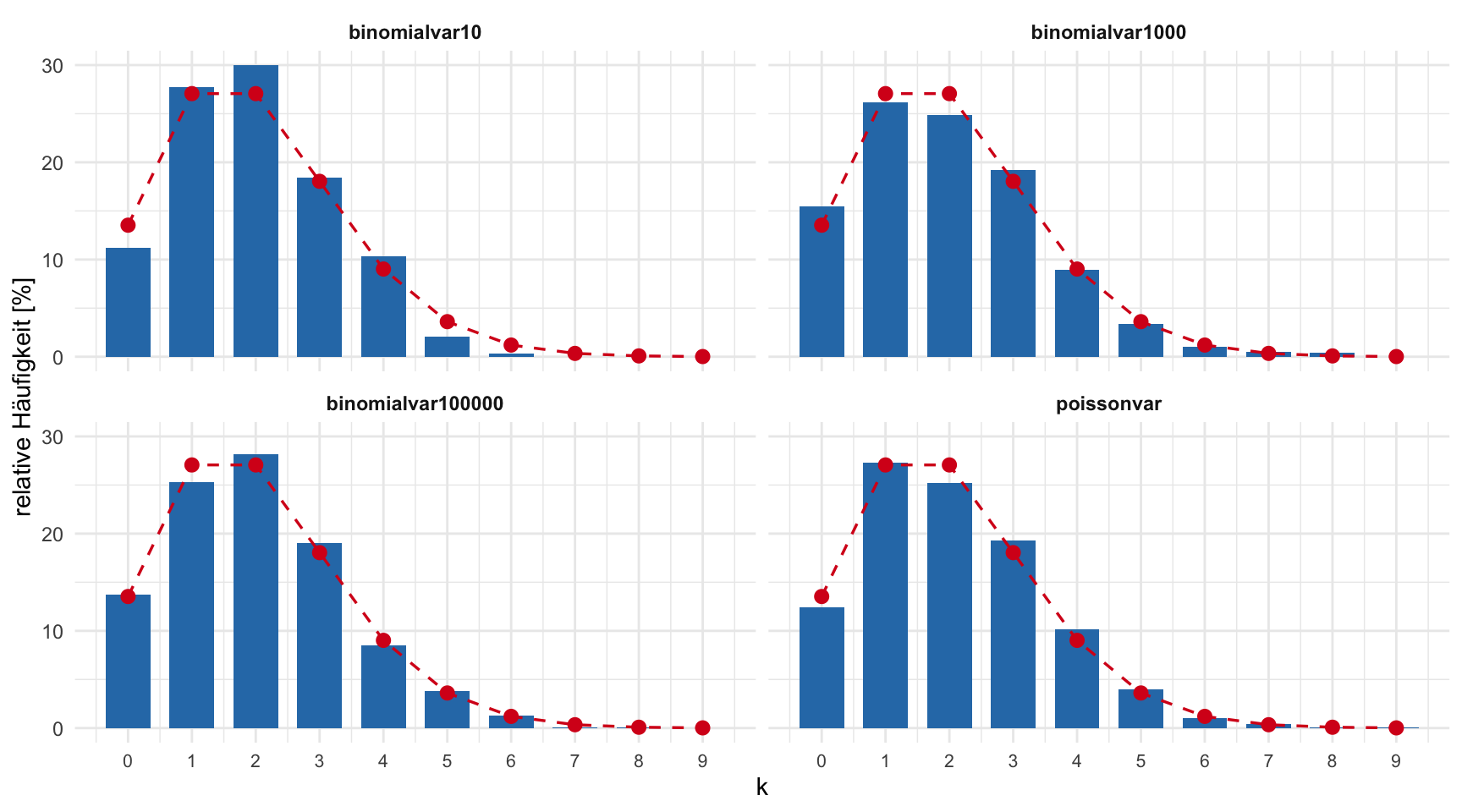
Die Poisson-Verteilung \(\text{Po}(\lambda)\) lässt sich als Grenzfall einer Binomialverteilung \(\text{Bi}(n;\, p)\) auffassen, wo \(n \to \infty\) und gleichzeitig \(p \to 0\) so, dass das Produkt \(\lambda = n \cdot p\) konstant bleibt. Dies soll hier illustriert werden.
Erzeugen Sie mit 1000 Beobachtungen eine Variable binomialvar10, die binomialverteilte Zufallszahlen mit \(n = 10\) und \(p = 0.2\) enthält, der Binomialverteilung \(\text{Bi}(10;\, 0.2)\) entsprechend. Erzeugen Sie anschliessend sukzessive weitere Variablen mit binomialverteilten Zufallszahlen; dabei soll \(n\) schnell zunehmen und gleichzeitig \(p\) so abnehmen, dass das Produkt \(\lambda = n \cdot p\) konstant bleibt. Führen Sie diesen Prozess so lange durch, bis sich die binomialverteilten Variablen einer entsprechenden poissonverteilten Variable poissonvar nähern (welche muss das sein?). Stellen Sie die Verteilungen geeignet grafisch dar.
Der Poisson-Grenzwertsatz besagt: Für \(n \to \infty\) und \(p \to 0\) mit \(\lambda = n \cdot p = \text{const}\) gilt
\[B(n;\, p) \;\xrightarrow{\;n \to \infty,\; p \,=\, \lambda/n\;}\; \text{Po}(\lambda)\]
Die Wahrscheinlichkeitsfunktion der Poissonverteilung lautet:
\[P(X = k) = \frac{\lambda^k \cdot e^{-\lambda}}{k!}, \quad k = 0, 1, 2, \ldots\]
Konkrete Parameterwahl (\(\lambda = n \cdot p = 2\) konstant):
| Variable | \(n\) | \(p = \lambda/n\) | \(\lambda = n \cdot p\) |
|---|---|---|---|
| binomialvar10 | 10 | 0.2 | 2 |
| binomialvar1000 | 1 000 | 0.002 | 2 |
| binomialvar100000 | 100 000 | 0.00002 | 2 |
| poissonvar | \(\to \infty\) | \(\to 0\) | 2 |
Die Grenzverteilung ist \(\text{Po}(2)\), da \(\lambda = n \cdot p = 2\) konstant bleibt.
Konvergenz der Wahrscheinlichkeitsfunktionen: Für beliebiges \(k\) gilt:
\[\binom{n}{k}\left(\frac{\lambda}{n}\right)^{\!k}\!\left(1-\frac{\lambda}{n}\right)^{\!n-k} \;\xrightarrow{n\to\infty}\; \frac{\lambda^k \cdot e^{-\lambda}}{k!}\]
Für eine gute Annäherung wird \(n\) recht gross gebraucht (z.B. \(n \geq 10\,000\)), da \(p\) sehr klein werden muss.
set.seed(42)
lambda <- 2 # n * p = konstant
# Bi(n; lambda/n) mit wachsendem n
binomialvar10 <- rbinom(n_sim, size = 10, prob = lambda / 10)
binomialvar1000 <- rbinom(n_sim, size = 1000, prob = lambda / 1000)
binomialvar100000 <- rbinom(n_sim, size = 100000, prob = lambda / 100000)
# Grenzverteilung: Po(2)
poissonvar <- rpois(n_sim, lambda = lambda)# Empirische relative Häufigkeiten in langer Form
df_pois <- tibble(
binomialvar10 = binomialvar10,
binomialvar1000 = binomialvar1000,
binomialvar100000 = binomialvar100000,
poissonvar = poissonvar
) |>
pivot_longer(everything(), names_to = "Variable", values_to = "x") |>
mutate(Variable = factor(Variable,
levels = c("binomialvar10", "binomialvar1000",
"binomialvar100000", "poissonvar"))) |>
count(Variable, x) |>
group_by(Variable) |>
mutate(rel = n / sum(n) * 100) |>
ungroup()
# Theoretische Po(2)-Wahrscheinlichkeiten
k_max <- max(df_pois$x)
df_po_theorie <- tibble(
x = 0:k_max,
rel = dpois(0:k_max, lambda = lambda) * 100
)
ggplot(df_pois, aes(x = x, y = rel)) +
geom_col(fill = blau, width = 0.7) +
geom_point(data = df_po_theorie, aes(x = x, y = rel),
colour = rot, size = 2.5) +
geom_line(data = df_po_theorie, aes(x = x, y = rel),
colour = rot, linewidth = 0.6, linetype = "dashed") +
facet_wrap(~ Variable, nrow = 2) +
scale_x_continuous(breaks = 0:k_max) +
labs(x = "k", y = "relative Häufigkeit [%]") +
theme_minimal(base_size = 11) +
theme(strip.text = element_text(face = "bold"),
axis.text.x = element_text(size = 8))